ML: Lineare Regression
Im maschinellen Lernen stellt die lineare Regression eine der einfacheren statistischen Verfahren dar. Das Ziel ist das Finden einer linearen Gleichung, die eine Variable berechnet, die in Abhängigkeit zu einer oder mehreren bekannten Variablen steht.
Sehr einfach ausgedrückt, geht es um das Finden einer Trendlinie, wie manche dies aus Excel kennen.
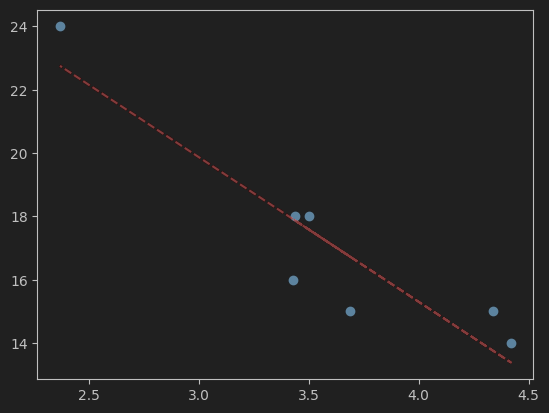
Alles, was hier beschrieben ist, ist natürlich nicht vollständig (weil umfangreiches Thema, weil ich es nicht besser weiß, …). Es soll einfach ein erster Eindruck vermittelt werden. Bestimmte Themenbereiche werde ich nachträglich ergänzen.
Technologie-Stack
Es gibt natürlich viele Wege ans Ziel, aber als Programmiersprache erster Wahl im Bereich ML hat sich Python durchgesetzt, da es sich hierbei um eine sehr einfach zu lernende Programmiersprache handelt und es sehr viele frei verfügbare ML-Bibliotheken gibt.
In meinen Beispielen verwende ich folgende Bibliotheken, die einfach mit pip installiert werden können:
pip install numpy
pip install pandas
pip install matplotlib
pip install seaborn
pip install scikit-learnVorarbeiten
Vor dem Trainieren eines Modells benötigen wir Testdaten. Hierfür verwende ich „Automobile Dataset“ von Kaggle.
# Import der benötigten Pakete
import pandas as pd
import numpy as np
# Laden der CSV-Datei
df = pd.read_csv(
"data.csv",
delimiter=",",
thousands=None,
decimal=".")Mit dem folgenden Befehl könnten die Series inkl. Datentyp aus dem DataFrame ausgegeben werden.
df.info()
Wie wir sehen, sind bei einigen Serien falsche Datentypen hinterlegt, die wir korrigieren müssen (zumindest bei denen, die für uns relevant sind).
Eine weitere wichtige Funktion ist die folgende, die uns Details zu den Werten zurückgibt.
df.describe(include="all")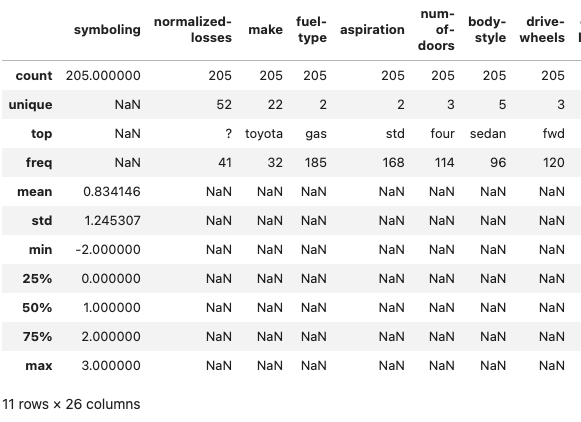
Im Ergebnis sind alle Serien aufgelistet. Ich habe den Screenshot nur gekürzt, damit das Bild lesbar bleibt.
Was genau sehen wir hier?
- count = Anzahl der nicht-leeren Werte
- unique = Anzahl der eindeutigen Werte (nur bei Objekten und Strings)
- top = häufigster Wert (nur bei Objekten und Strings)
- freq = Häufigkeit des häufigsten Wertes
- mean = Durchschnitt (nur bei Nummern)
- std = Standardabweichung (nur bei Nummern)
- min = Minimaler Wert (nur bei Nummern)
- 25% = höchster Wert des ersten Quartils (nur bei Nummern)
- 50% = höchster Wert des zweiten Quartils – also der Median (nur bei Nummern)
- 75% = höchster Wert des dritten Quartils (nur bei Nummern)
- Max = Maximaler Wert (nur bei Nummern
Unsere Unbekannte für das Modell ist der „price“. Dieser ist aktuell vom Datentyp „object“. Da wir diesen allerdings für das Training unseres Modells benötigen, müssen wir als erstes die Daten bereinigen und den Wert in eine Nummer umwandeln.
Alles, was keine Nummer ist, ist für uns nicht relevant. Die Werte können wir durch NaN ersetzen.
# coerce definiert, dass Fehler durch NaN ersetzt werden sollen
df["price"] = pd.to_numeric(df["price"], errors="coerce")Das Gleiche machen wir jetzt noch für „horsepower“, da diese Serie ev. auch Einfluss auf den Preis hat.
df["horsepower"] = pd.to_numeric(df["horsepower"], errors="coerce")Möglicherweise hat auch der „fuel-type“ eine Auswirkung auf den Preis. Hierbei handelt es sich aktuell um eine Serie mit den Werten „gas“ oder „diesel“.
df["fuel-type"].unique()
Zum Trainieren des Modells benötigen wir Nummern und keine Texte. Eine Möglichkeit das Problem zu Lösen ist, dass wir aus der Serie „fuel-type“ mehrere Serien (pro Wert eine) mit den Werten 0 und 1 machen (auch One-Shot bezeichnet).
fuel_series = pd.get_dummies(df["fuel-type"], prefix="fuel")
df = df.drop(columns=["fuel-type"]).join(fuel_series)
df.info()
Zur Vereinfachung des Beispiels werden ab jetzt nur noch ein paar Serien verwendet, auch wenn vermutlich manche der entfernten Serien eine Relevanz auf den Preis haben.
df = df[["price", "fuel_diesel", "fuel_gas", "horsepower", "engine-size"]]
df.describe(include="all")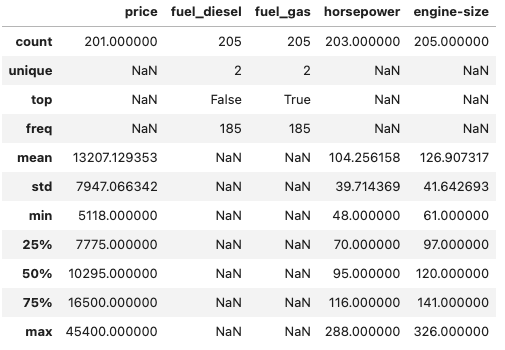
Als Nächstes schauen wir uns die Zusammenhänge zwischen den Eigenschaften mit Hilfe einer Scatter Matrix an.
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df[["price", "horsepower", "engine-size"]], diag_kind="kde")
plt.show()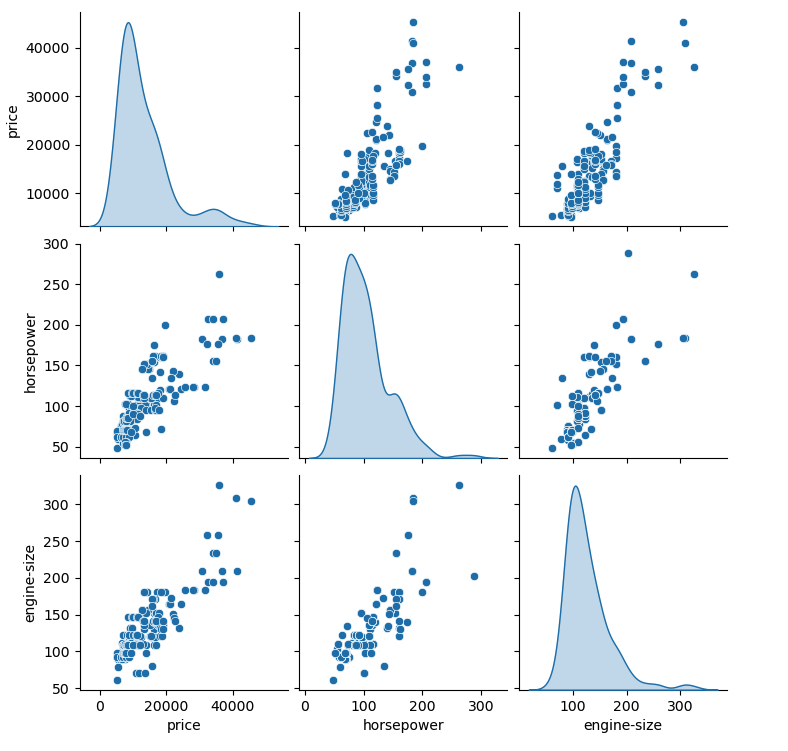
Eine solche Matrix ist hilfreich bei der Analyse, welche Features in einem Zusammenhang stehen. Wie unschwer erkennbar, stehen „engine-size“ und „horsepower“ zum Preis in einem Verhältnis, wenn auch nicht ganz genau.
Eine Alternative, ohne Grafik, ist die Anzeige der Korrelation zwischen den Eigenschaften.
df[["price", "horsepower", "engine-size"]].corr()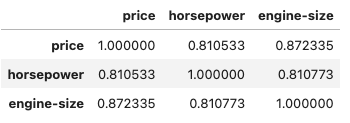
Werte, die nahe -1 oder 1 sind, haben eine hohe Korrelation zueinander.
Bevor wir jetzt mit dem Training des Modells starten, löschen wir noch NaN Werte. Alternativ können diese mit anderen Werten bestückt werden.
df = df.dropna()Modell erstellen und trainieren
Als erstes splitten wir unsere Daten in Trainingsdaten und Testdaten.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# X = Features
X = df[["horsepower", "engine-size", "fuel_gas", "fuel_diesel"]]
# y = Prediction/Vorhersagewert
y = df["price"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)Das war’s 🫣.
OK, fast. Spannend sind die Fehler, die unser Modell jetzt hat. Hierfür gibt es drei Kennzahlen:
MAE – mean absolute error
Der mittlere absolute Fehler misst die durchschnittliche Abweichung zwischen Vorhersage und tatsächlichem Wert, indem die Differenz der beiden Werte gezogen wird (absolut).
Ein niedriger Wert deutet darauf hin, dass die Vorhersage genau ist. Der MAE ist unempfindlich gegen Ausreißer (siehe MSE).
MSE – mean squared error
Der mittlere quadratische Fehler misst die durchschnittliche quadrierte Differenz zwischen Vorhersage und tatsächlichem Wert.
Wie schon der MAE bedeutet ein niedriger Wert, dass die Vorhersage genau ist. Da die Differenz allerdings zum Quadrat genommen wird, haben Ausreißer hierbei eine höhere Auswirkung.
RMSE – root mean squared error
Hierbei wird die Quadratwurzel des MSE gezogen, wodurch die Einheit für den Fehler wieder der Einheit der Vorhersage entspricht, wobei Ausreißer nach wie vor höher gewichtet werden.
from sklearn.metrics import mean_absolute_error, mean_squared_error, root_mean_squared_error
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rootmse = root_mean_squared_error(y_test, y_pred)Zum Abschluss noch ein bisschen Mathematik 🤪
y = b + f1x1 + f2x2 + ...y = Ergebnis
b = Bias; konstanter Wert, der zur Vorhersage addiert wird
f = Feature
x = Gewichtung des Features
Beim Training des Modells wird der optimale Bias und die Gewichtung für die Features bestimmt. Diese Werte können auch ausgegeben werden, um nachzuvollziehen, welche Features vom Modell besonders stark berücksichtigt wurden.
Formel
Prediction = Bias + (Weight1 * Feature value1) + (Weight2 + Feature value2) + …
Prediction = Vorhersage – also das, was wir berechnen wollen
Bias = konstanter Wert, der zur Vorhersage addiert wird. Damit kann auch, wenn alle Features Null sind, ein Wert berechnet werden
Weight = definiert, welchen Einfluss ein Feature auf die Prediction hat.
Feature = …
f = Feature
x = Gewichtung
# Bias
model.intercept_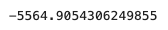
for feature, coef in zip(X.columns, model.coef_):
print(f"{feature}: {coef}")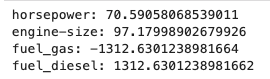
Und was sagt uns das jetzt? Dass wir uns dringend nochmal mit den Features beschäftigen sollten 😉